AI 에이전트의 진짜 비용은 코드가 아니라 검증에 있다
논문이 측정한 것
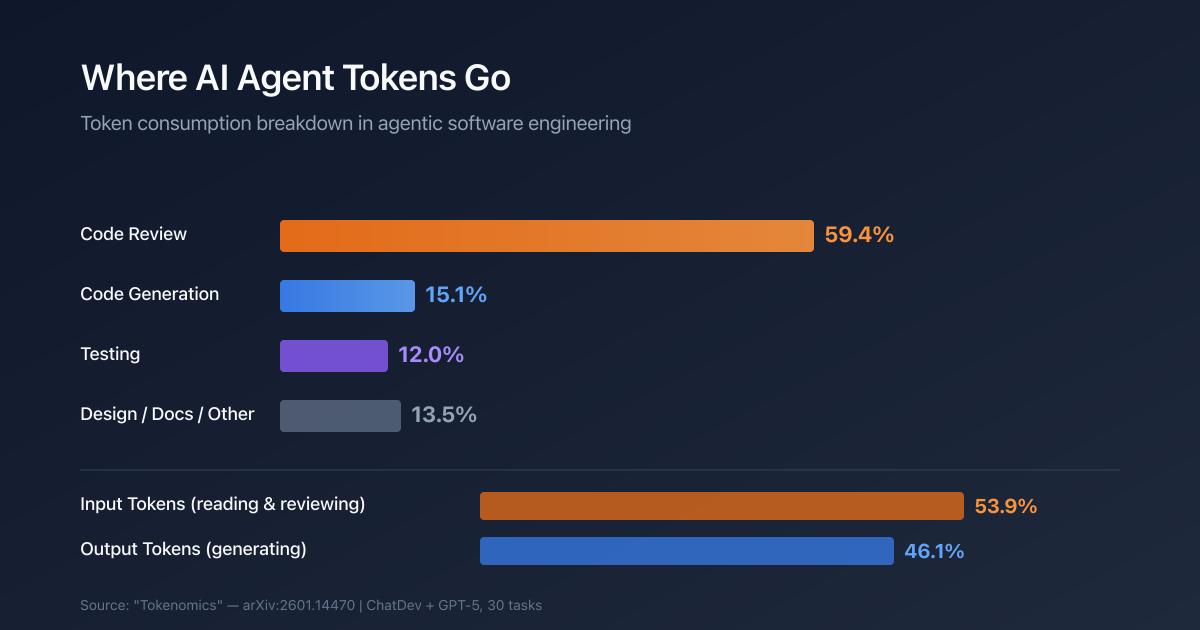
arXiv에 올라온 "Tokenomics: Quantifying Where Tokens Are Used in Agentic Software Engineering"(2601.14470)은 에이전트 기반 SW 개발에서 토큰이 어디에 얼마나 쓰이는지를 실제로 쟀다. ChatDev 프레임워크와 GPT-5 추론 모델로 소프트웨어 개발 태스크 30개를 돌리면서, 설계·코딩·코드 완성·리뷰·테스트·문서화 6단계별로 토큰 소비량을 기록했다.
숫자
코드 리뷰 단계가 전체 토큰의 59.4%를 차지했다. 코드 생성은 15.1%. 비율로 보면 리뷰가 생성의 거의 4배다.
입력 토큰이 53.9%라는 것도 같은 맥락이다. 에이전트들이 새로운 코드를 만들어내는 것보다, 이미 있는 코드를 읽고 판단하고 수정하는 데 더 많은 토큰을 쓴다.
사람 팀도 비슷하다. 시니어 개발자일수록 코드 작성보다 리뷰에 시간을 더 쓰는 경향이 있다. 에이전트가 같은 패턴을 따르고 있는 셈이다.
비용 예측에 실제로 어떤 영향을 주는가
이 데이터에서 바로 끌어낼 수 있는 실용적인 시사점이 몇 가지 있다.
첫째, 에이전트 비용 예산을 잡을 때 "얼마나 많은 코드를 생성할 것인가"는 잘못된 질문이다. "몇 번의 리뷰 사이클을 거칠 것인가"가 실제 청구서를 결정한다. 리뷰 횟수가 늘수록 비용이 선형이 아닌 복리로 늘어날 수 있다.
둘째, 에이전트가 리뷰를 종료하는 조건이 명확하지 않으면 루프가 불필요하게 반복된다. 언제 "충분히 좋다"고 판단할지 — 이 기준을 시스템 설계 단계에서 정해두지 않으면 비용이 통제 밖으로 나갈 수 있다.
셋째, 멀티 에이전트 시스템에서 역할 분리가 명확할수록 리뷰 루프가 줄어드는 경향이 있다. 서로 역할이 겹치는 에이전트들이 같은 코드를 여러 번 검토하는 상황이 비용 비효율의 주요 원인 중 하나다.
리뷰 루프는 버그인가, 기능인가
리뷰에 토큰이 많이 든다는 사실 자체가 문제는 아니다. 에이전트 시스템이 스스로를 교정하고 있다는 뜻이기도 하다. 진짜 질문은 그 교정이 효과적인가다.
리뷰 루프에서 실제로 버그가 줄고 코드 품질이 오른다면 투자다. 같은 지적이 반복되고 수정이 일어나지 않는다면 낭비다. 비용 최적화의 출발점은 리뷰를 줄이는 게 아니라, 리뷰가 실제로 작동하고 있는지 확인하는 것이다.